
A Sydney-based university researcher leading a study of the cloud computing platforms of Amazon, Google and Microsoft yesterday revealed some of the reasons cloud services provide unpredicatable results under stress testing.

Anna Liu, associate professor in services engineering at the school of computer science and engineering at the University of NSW (UNSW) told iTnews last week that response times to queries sent to Amazon's EC2, Google's AppEngine and Microsoft's Azure platform varied by a factor of 20 depending on the service and time of day the cloud was accessed.
Liu today told the Architecture Australia Forum that throttling, power failures and deliberate design constraints were among the reasons for the unpredictability.
"While scalability works nicely for these platforms, availability is an interesting question," she told the Sydney audience. "We have noticed outages."
Liu said that with the effect of network latency issues included, stress tests revealed error rates of up to 12 percent - these being requests from the Sydney research headquarters to the U.S.-based cloud provider that didn't make the round trip back.
Once network latency was removed as a factor (due to instrumentation loaded onto the cloud platform itself), error rates were far lower, but still of concern to enterprise application developers.
While stressing that the numbers presented were only 'snapshots in time', Liu showed two slides to illustrate occasions in which availability became an issue.
In the first slide (below), tests of Google's AppEngine showed average failure rates of 0.04 per cent, along with some examples of the error messages received when the service failed.
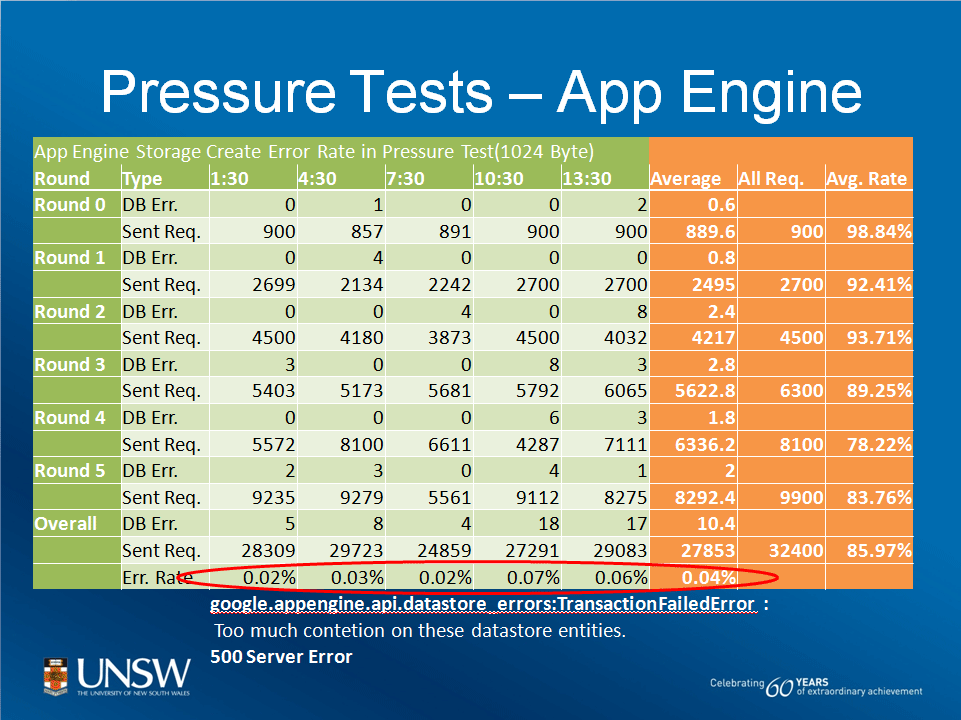 |
| Snapshot of Google AppEngine stress test (Source: Anna Liu) |
The horizontal axis represents time samples (time of day), while the vertical axis records a gradual increase in the number of concurrent users connecting to the service.
Liu said that after comparing notes with technicians at Google's engineering labs, she discovered that these failures were in fact a design feature of the AppEngine service.
They were designed, she said, to cope with potential denial of service attacks.
"It was a feature they needed to avoid potential attacks," she said. "They found they could fix it easily by digging in to their back-end infrastructure and changing a few parameters to accept a greater volume of requests."
Liu said such design features should be expected and that they were "consistent with [Google's] simple programming model for your average web developer."
In a second slide [below], Liu showed much higher failure rates for tests of Amazon.com's SimpleDB service.
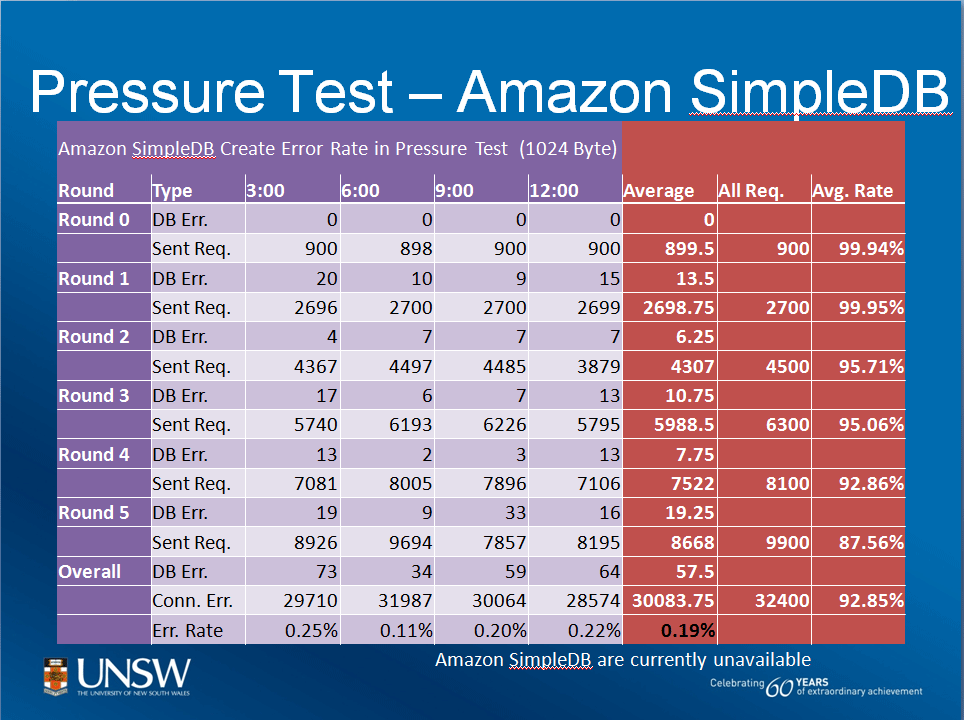 |
| Snapshot of Amazon SimpleDB stress test (Source: Anna Liu) |
Liu said these results correlated with a "power and back-up generator failure" Amazon.com experienced at the time.
"You will have some unpredictability in large-scale environment, at least until we get all of these issues sorted out," Liu said.
Liu later told iTnews that she felt the challenge for developers wasn't so much about availability but unpredictability around when outages will hit.
"From an architecture perspective, you need to have a plan for when outages hit," she said.
Liu said that it was difficult to do apple-for-apple comparisons of the three platforms considering their different use cases.
"It is not like the (database benchmarking organisation) TPCC, which measures the performance of relational databases," she said. "There is a well-defined set of capabilities and usage scenarios for a relational database, not so for a cloud service."
But Liu said one of her eventual aims is to build up a historical view of the performance of the three cloud platforms and create a simple web application to help application architects choose which suits their requirements.
"Ideally, you would be choosing an application profile, and be given the response time of a query using x service on y cloud platform," she said.



.jpg&h=140&w=231&c=1&s=0)
.jpg&h=140&w=231&c=1&s=0)





 iTnews State of Data & AI Breakfast
iTnews State of Data & AI Breakfast
 Forrester's AI Forum Sydney
Forrester's AI Forum Sydney
 The 2026 iAwards
The 2026 iAwards
.jpg&w=120&c=1&s=0) Integrate 2026
Integrate 2026
 Security Exhibition & Conference
Security Exhibition & Conference











_(1).jpg&h=140&w=231&c=1&s=0)



