
Telstra is running deep learning algorithms over its Networks data to predict equipment failures before they occur and to find ways to address voice and SMS scams.

Data science (Networks) team manager Tim Osborne revealed the project, which is codenamed Telstra AI Lab or TAIL, in a presentation to IBM’s Think 2020 conference overnight.
TAIL is operating on a still-evolving applied data science platform pieced together with IBM’s assistance.
It uses a mix of existing Cisco UCS C240s and new IBM Power System AC922s for compute, and a Kubernetes-based stack on top, including Kubeflow, which is used to run machine learning algorithms on Kubernetes.
Osborne said TAIL was supported by a team of 25 data scientists and date engineers, who worked “with network engineering folks end-to-end across the business, looking to solve some of their most challenging problems with data science.”
He characterised the earlier challenges that TAIL is working on as network optimisation, power optimisation, and fraud and other telco-related scams.
“Network optimisation for us is about being able to be predictive and to detect and diagnose things that we couldn't see,” he said.
“[It’s about] being able to drive proactive outcomes in our operations, proactive outcomes for our customers, and also trying to think about how we have networks that are self-organised.
“Being able to use a deep learning algorithm to understand machine code and figure out what all that means, so that we can fix something before it fails, is really cool, and that's what we're doing at the moment.”
On the power optimisation side, Osborne said the company is exploring heating, ventilation and air conditioning (HVAC) optimisation, though he did not elaborate on the specifics.
He also said TAIL is being used to crack down on telecommunications scams, an area where Telstra and other carriers have faced regulatory pressure over the past year.
“There are a lot of scams going on globally in the mobile space - people sending scams with SMS; people calling up and asking you to call back, and it's very expensive to call. We're employing countermeasures [against these now].
“We're also interested in people that are exploiting our products - using our products and costing us a lot of money that shouldn't be in their pockets, [that] shouldn't be taken from our shareholders, [and] shouldn't be impacting our customers.
“We've found a great way to prevent those things from happening.”
The work dates back less than six months, with Osborne revealing that Telstra had engaged IBM to stand up an applied data science platform to enable TAIL to operate.
“We had the people, the smarts; we had the use cases, the opportunities were there for us; and we had the data,” he said. “We just didn't have a platform.
“Going back to December 2019, we started a partnership with IBM. This partnership has been absolutely exemplary.
“We have symbiotic end states. IBM was very interested in getting more experience and exposure to using their platforms with Kubernetes and Kubeflow, and we were very interested in using those and scaling that up within our business.
“We now have an incredible machine learning platform, [and] our data scientists are now fed and watered.”
Osborne said the data science platform enabled his team to perform rapid investigations and to scale up to production use cases quickly, based on the needs of the Networks business.
“As we become more popular, which is what's happening in the business at the moment, we can add more machines, we can put more into the cluster and scale up the resources as we need it to be,” he said.
Under the hood
IBM’s AI technical specialist Adam Makarucha said the applied data science platform was deployed over December and January.
It has initially been built on top of native Kubernetes but there are plans to move it to Red Hat's OpenShift container management platform, now that version 4.3 of OpenShift supports Power System.
On the hardware side, Marakucha said there is a “total of six machines, six nodes.”
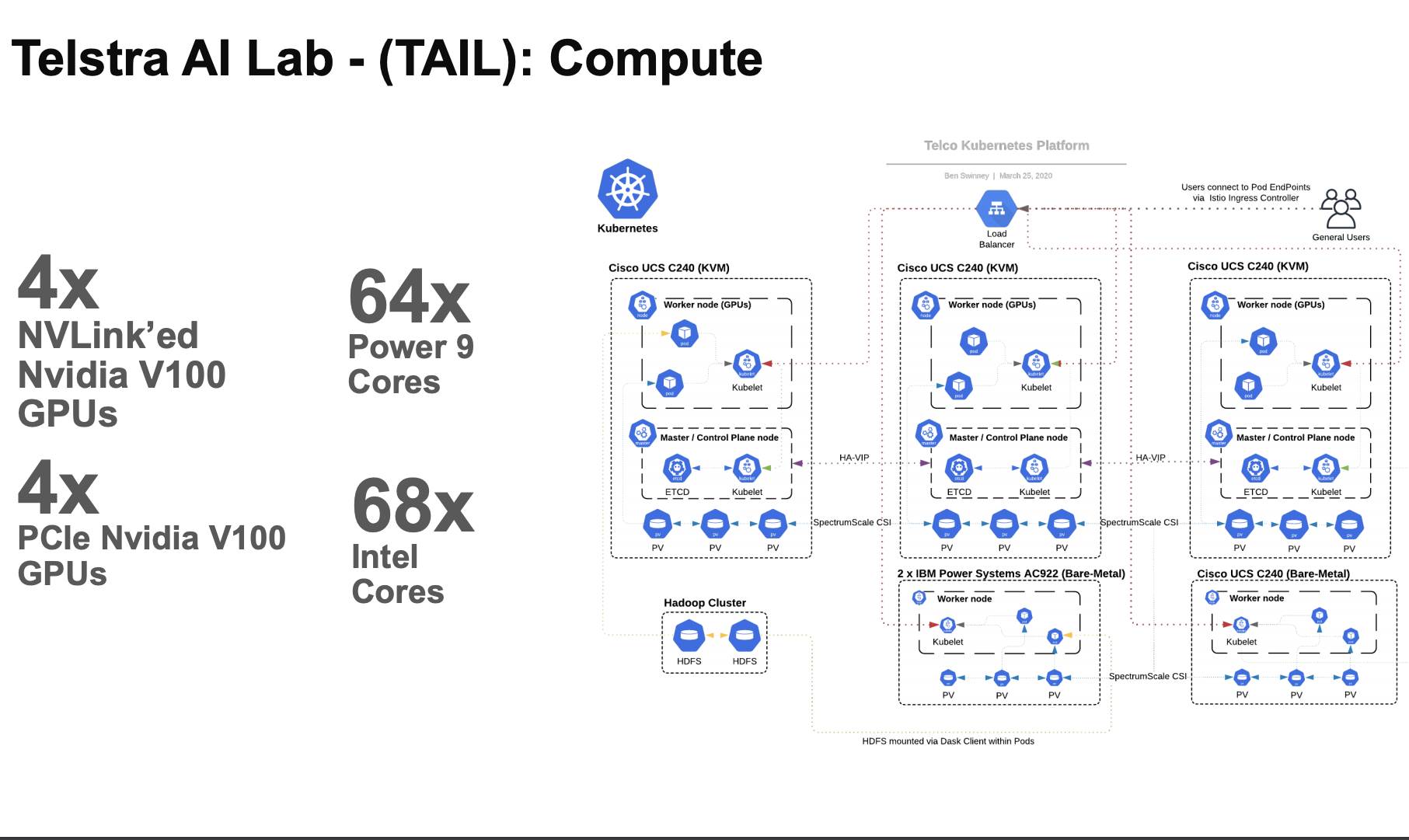
“It doesn't seem like a lot of compute, but what is key in this deployment is each one of these nodes has GPU acceleration,” he said.
“That really means that the total amount of compute and power in this machine actually far exceeds what you would expect out of a six node system. In fact, it's probably in the order of 160 nodes in total performance.
“There is a total of 237.6 Teraflops of [GPU] single precision performance in this platform.”
Marakucha said that although Telstra wanted to use the Power System AC922s, it also wanted to reuse Cisco UCS hardware and other equipment and services it had already invested in.
“We could have just gone down the route of using an x86 based cluster but Telstra wanted to bring in the AC922s specifically because of the advantage they have for doing deep learning on very large data sets and large models,” Marakucha said.
While such mixed environments could be hard to manage, he said, Kubernetes was able to take on much of that.
Marakucha also said that the environment had been configured to set some limits on the amount of resource a single data scientist could use at any one time, to prevent it becoming monopolised.
“If you're a data scientist out there, you probably do what I do when I do any data science: I try and get as many cores and as much compute as I possibly can, even if I'm not going to use it all at the same time,” he said.
“Lots of the data scientists in this environment were doing the same thing, which meant we quickly ran out of compute, because we were consuming all the cores.
“So what we did is we hard locked the number of cores down to two and this meant we had flexibility because Kubernetes is nice in that if you ask for a request of two cores, you are guaranteed that as a minimum but it allows you to scale to more if there is more available.
“We've just locked some configurations to prevent over-provisioning.”


.jpg&h=140&w=231&c=1&s=0)



.png&w=100&c=1&s=0)



 SAP NOW AI Tour ANZ
SAP NOW AI Tour ANZ
 Forrester's AI Forum Sydney
Forrester's AI Forum Sydney
 The 2026 iAwards
The 2026 iAwards
.jpg&w=120&c=1&s=0) Integrate 2026
Integrate 2026
 Security Exhibition & Conference
Security Exhibition & Conference











_(1).jpg&h=140&w=231&c=1&s=0)



