
Johnson & Johnson is planning to purge the final remnants of tape storage from its enterprise data centres within 18 months.

The multinational pharmaceutical and consumer goods maker first launched a program of work it called “Tapeless” back in early 2014.
The company wanted to kill its reliance on tape for backup and recovery, which it saw as a first step towards shifting its global enterprise data centre environment to a software-defined data centre (SDDC) operating model.
J&J runs paired primary-secondary data centres for its North America, EMEA and Asia Pacific regions. The primary facility is J&J’s while the secondary site is typically co-lo.
ITS senior manager for SDDC global core infrastructure services, backup and recoverability, Frank Floyd, told VMworld 2017 that tape had been central to J&J’s backup processes until 2014.
“We would back up, we’d go to a (NetBackup) media server, we would send it off to a Quantum tape library using LTO-type tapes, and then we’d use Iron Mountain and send it offsite,” Floyd said.
“That worked well for a while … for DR, but it doesn’t work well for quick onsite recovery given that we have to recall every single tape and wait hours and hours for Iron Mountain to find the tape, send it back to us, find the onsite person to get it in the tape library etc.”
The company decided to switch from tape to EMC Data Domain units: first the DD990s, and now DD9800s since the former was end-of-lifed.
The switch enabled J&J to go “97 percent tapeless” in its enterprise data centres.
“There’s a few legacy systems that still run tape,” Floyd said.
“I have 36 tape drives as the only thing remaining in the [data centres], and I hope to get rid of them in the next 18 months.”
One of the key reasons J&J wanted to get rid of tape was to allow it to move to an SDDC environment.
“SDDC is built on tapeless,” Floyd said.
“That was a precursor to allowing us to go SDDC and then to enable [the use of] automation technologies for backup and recovery.”
Going SDDC
The business case for SDDC was approved back in 2014. Following a successful proof-of-concept (PoC), the first SDDC deployment occurred across the two Asia Pacific data centres at the end of 2014.
By the end of 2015, all six J&J data centres across the globe ran as an SDDC.
Each location runs what J&J calls SDDC ‘pods’- the physical hardware and software stacks that underpin the SDDC functionality.
The hardware consists of HPE blades, 3PAR 8400 storage arrays (7400s in the initial 2014 pod design) and Cisco networking equipment, along with the Data Domain units for backup. The software stack is almost all VMware.
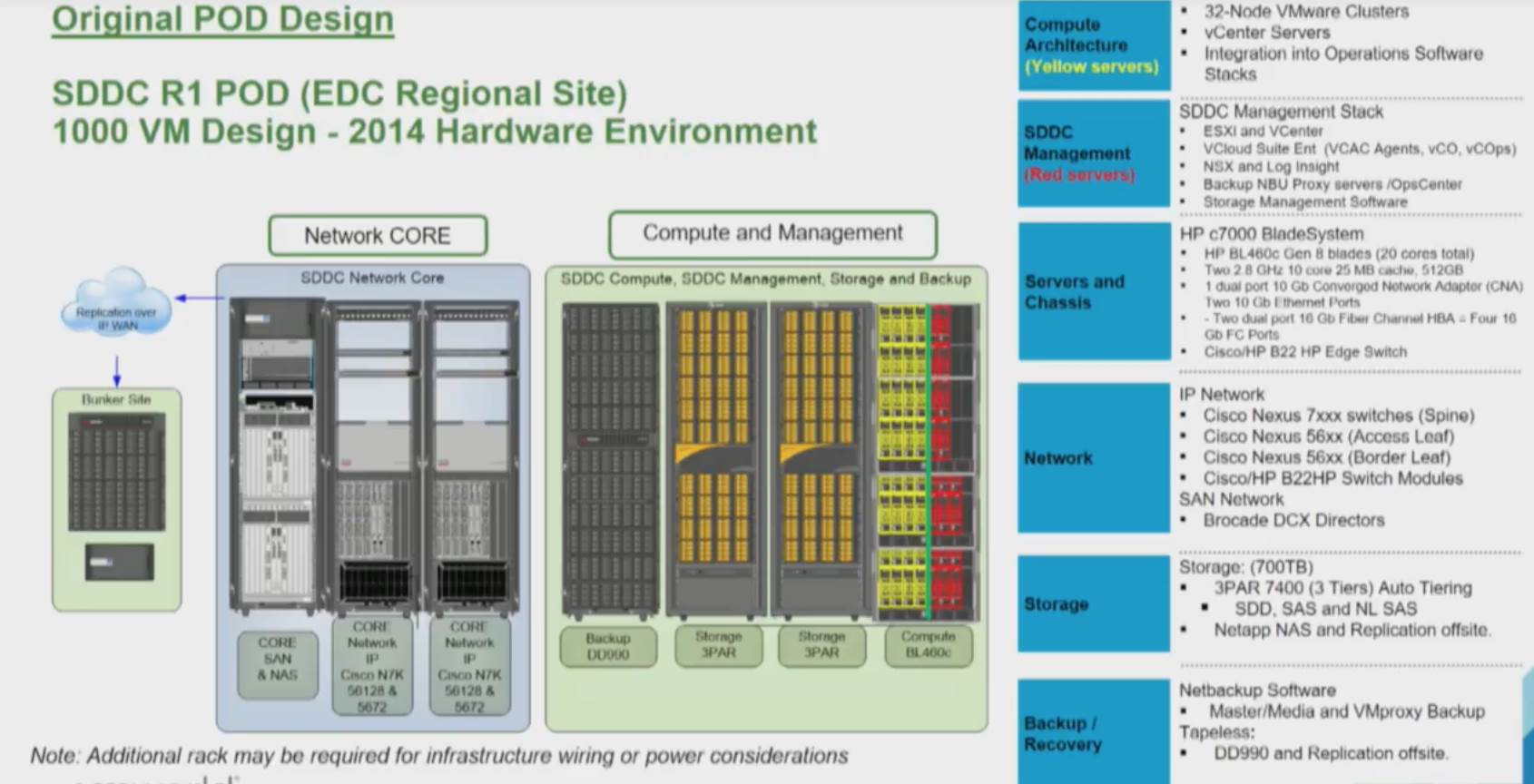
The original J&J SDDC pod design; some hardware such as the 3PARs, blades and Data Domain hardware has been updated.
J&J’s users are currently able to spin up VMs running Windows or Linux, consume database-as-a-service (Oracle, SQL) and host some “SAP blueprints”.
Provisioning times have dropped weeks to hours. Prior to SDDC, J&J’s ITS teams were split along technological boundaries, meaning that even provisioning a VM required many hand-offs to complete, which introduced delays.
As of August 2017 J&J had 18,678 workloads (VMs) running in the SDDC worldwide.
VADP adoption
One of the challenges Floyd faced with the structure of ITS was getting J&J’s VMware team to agree to enable VMware vSphere Storage APIs – Data Protection (VADP) for snapshot-based backups.
VADP is built into vSphere and is used in conjunction with other backup software; J&J uses it with Veritas’ NetBackup, with all backups stored on the Data Domain units in the primary and secondary facilities in each region.
Since Floyd’s backup team was one of ITS’ silos, it needed the internal VMware team’s buy-in to progress VADP adoption.
“Everybody had to work together in order to make solutions work,” Floyd said.
“Prior to SDDC, I couldn’t get our VMware folks convinced that VADP backups was the right thing to do.
“They did not want to take the storage overhead costs into account when they were provisioning their clusters.
“What we’ve seen is 65 percent of our workloads now can use VADP snapshot-based backups.
“Why do we use snapshot-based backups? [Because] we’ve been able to achieve a 45x reduction on the Data Domain storage. That alone saves us a ton on storage costs.”


.jpg&h=140&w=231&c=1&s=0)



.png&w=100&c=1&s=0)



 SAP NOW AI Tour ANZ
SAP NOW AI Tour ANZ
 Forrester's AI Forum Sydney
Forrester's AI Forum Sydney
 The 2026 iAwards
The 2026 iAwards
.jpg&w=120&c=1&s=0) Integrate 2026
Integrate 2026
 Security Exhibition & Conference
Security Exhibition & Conference











_(1).jpg&h=140&w=231&c=1&s=0)



