
We’ve barely scratched the surface of availability, but we hope you’ve got a bit of a taste for what’s possible.

PART THREE: AVAILABILITY TOOLS
Hopefully you now know some of the questions to ask.
All the major cloud providers (Amazon Web Services, Microsoft Azure, Rackspace) support the patterns described here, though the implementation details vary considerably.
Below we have attempted to do some of the heavy lifting for you by putting together a matrix of what each of the major and local providers offer:
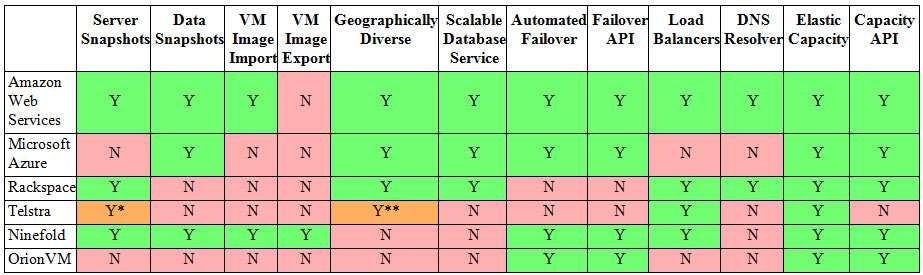
(click to enlarge)
*One snapshot only.
**Within Australia only.
KEY
- Server Snapshots: Can you take snapshots of the virtual machine state for point-in-time restore?
- Data Snapshots: Can you take snapshots of data areas (file or block) for point-in-time restore?
- VM Image Import/Export: Can you import or export VM images into/out of the cloud provider?
- Geographically Diverse: Is the hosting infrastructure available in multiple geographically diverse locations? i.e. two or more data centres more than 100kms apart.
- Scalable Database Service: an RDBMS provided as a service, as distinct from running your own DB on hosted servers. e.g. Amazon's RDB, SimpleDB and Microsoft SQL Azure.
- Automated Failover: The service detects VM failure and automatically restarts it, rather than the user having to detect and fix VM failure themselves.
- Failover API: an API provided for users to automate failover themselves, to take different actions on different failure events.
- Load Balancers: Load balancing between virtual servers provided as a cloud service, rather than externally hosted.
- DNS Resolver: DNS resolution provided as part of the cloud service, rather than externally hosted.
- Elastic Capacity: Ability to scale up, and down, on demand, for compute at a minimum, and preferably storage and network as well.
- Capacity API: Ability to manage capacity (scale up and down) through an API.
Further reading:
For more information, we thoroughly recommend the AWS Architecture site: Set up in the aftermath of a significant outage (previously covered by iTnews), it is designed to educate customers on how to set up their infrastructure to provide the level of availability and recoverability they need, even when AWS has another outage. We would strongly encourage other cloud providers to follow suit.


.jpg&h=140&w=231&c=1&s=0)

.jpg&h=140&w=231&c=1&s=0)
.png&w=100&c=1&s=0)




 iTnews State of Data & AI Breakfast
iTnews State of Data & AI Breakfast
 Forrester's AI Forum Sydney
Forrester's AI Forum Sydney
 The 2026 iAwards
The 2026 iAwards
.jpg&w=120&c=1&s=0) Integrate 2026
Integrate 2026
 Security Exhibition & Conference
Security Exhibition & Conference











_(1).jpg&h=140&w=231&c=1&s=0)



