
Google has made its Cloud Dataflow real-time data processing engine available as an open beta for developers.
Google first unveiled the product at its annual developer conference last June, but the service has been in private alpha until now.
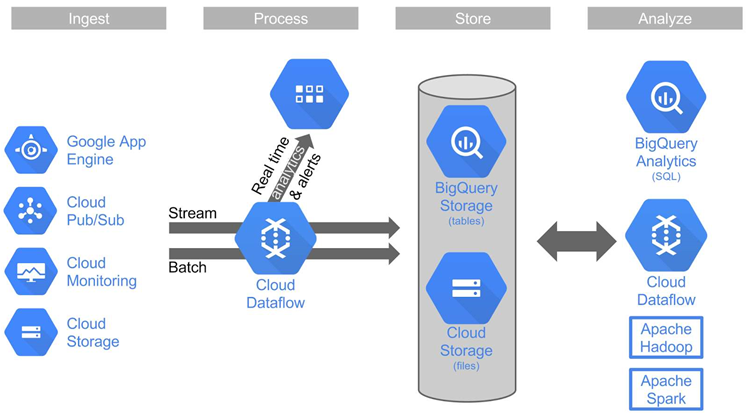
The data processing engine offers the ability to analyse live data as it comes in in real-time, and historical data in batch mode.
Google's intention is that Cloud Dataflow customers use the software development to write software that defines batch or streaming data-processing jobs for the service to run on Google Cloud Platform resources.
In a blog post about the announcement, Google product manager William Vambenepe emphasised the service's "NoOps" proposition, which, he wrote, "means the platform handles tasks and optimisations for you, freeing you up to focus on understanding and exploiting the value in your data".
"The platform auto-scales and optimises your infrastructure consumption, and eliminates unused resources like idle clusters," he wrote.
"You manage your costs by dialling up or down the number of queries and the latency of your processing based on your cost/benefit analysis. You should never have to re-architect your system to adjust your costs."
Google also today announced an immediate upgrade to its BigQuery tool for SQL analytics, one of several modular services which can be used alongside Cloud Dataflow.
Row-level permissions have been introduced to improve sharing and the default ingestion limit has been raised to 100,000 rows per second per table. BigQuery users can now also store their data in Google Cloud Platform European zones.

.jpg&h=140&w=231&c=1&s=0)


.jpg&h=140&w=231&c=1&s=0)

.png&w=100&c=1&s=0)



 SAP NOW AI Tour ANZ
SAP NOW AI Tour ANZ
 Forrester's AI Forum Sydney
Forrester's AI Forum Sydney
 The 2026 iAwards
The 2026 iAwards
.jpg&w=120&c=1&s=0) Integrate 2026
Integrate 2026
 Security Exhibition & Conference
Security Exhibition & Conference











_(1).jpg&h=140&w=231&c=1&s=0)



